Python网络爬虫6 - Scrapy爬取vmgirls
今天介绍一个妹子站点图片的爬取过程,站点唯美女生。站点结构非常简单,单独用requests库或者scrapy框架都可以。本文介绍的是使用scrapy框架爬取。

分析vmgirls站点
站点做的非常清新唯美,结构简洁明了,主页的主体部分以卡片形式展示各个主题的缩略图和简要介绍,但主页并不适合直接爬取。
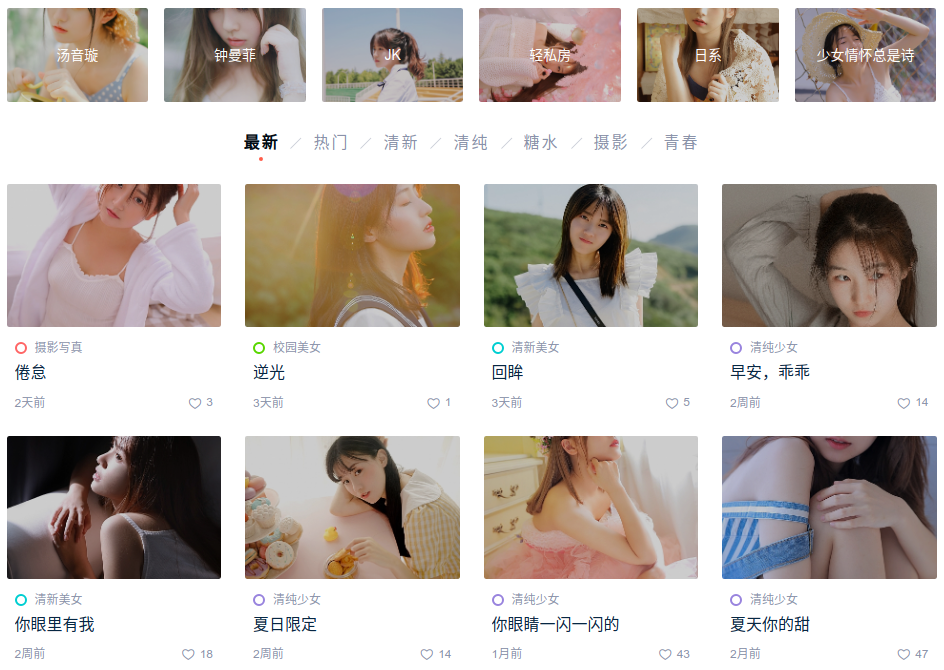
不过幸好该站点已经提供了站点地图,对于这种相对简单的网站,使用现成的网站地图简直事半功倍。
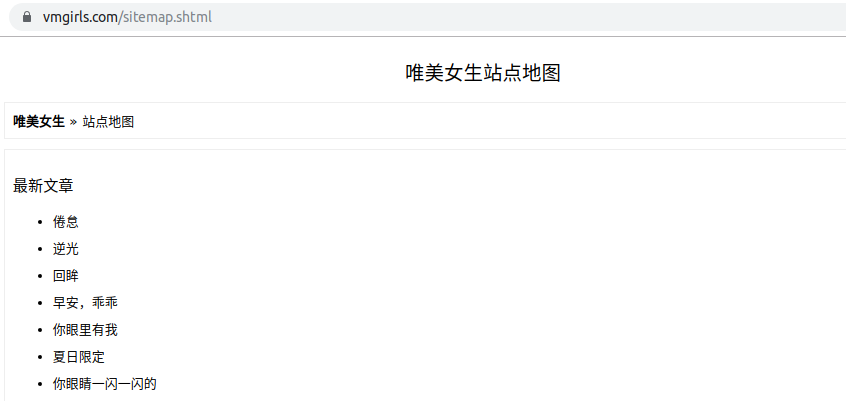
那么思路就很清楚了,首先通过站点地图获取所有主题页面的网址和标题,然后逐个爬取妹子页面,提取所有的图片url,然后下载到本地,每个主题页面的图片单独存放到一个文件夹中。
站点地图
本站点提供了两个站点地图:
第1个是面向用户的站点地图,从主页的导航栏就能找到;第2个(如下图)则是常规网站留给搜索引擎的站点地图,文件格式也是常规的xml
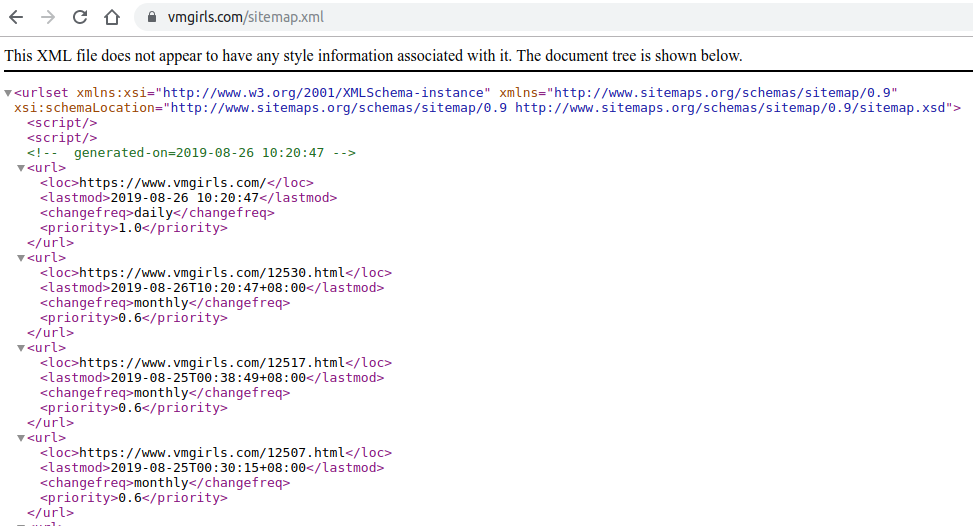
我使用wget指令获取两个文件,并进行了对比,发现sitemap.xml仅仅包含1000个网址,但是可视的站点地图包含1163个网址。说明留给搜索引擎的地图并不完整,而且相比较之下,sitemap.shtml所占的文件大小要比sitemap.xml还要小,这是因为sitemap.xml因其格式问题,带有大量重复信息。
➜ tmp ls -lh
total 320K
-rw-r--r-- 1 litreily litreily 132K 8月 26 17:25 sitemap.shtml
-rw-r--r-- 1 litreily litreily 186K 8月 26 20:44 sitemap.xml
所以,不管是考虑完整性,还是文件大小,我们都有理由选择sitemap.shtml作为爬取的第一个网页。
下面来看看站点地图的html结构:
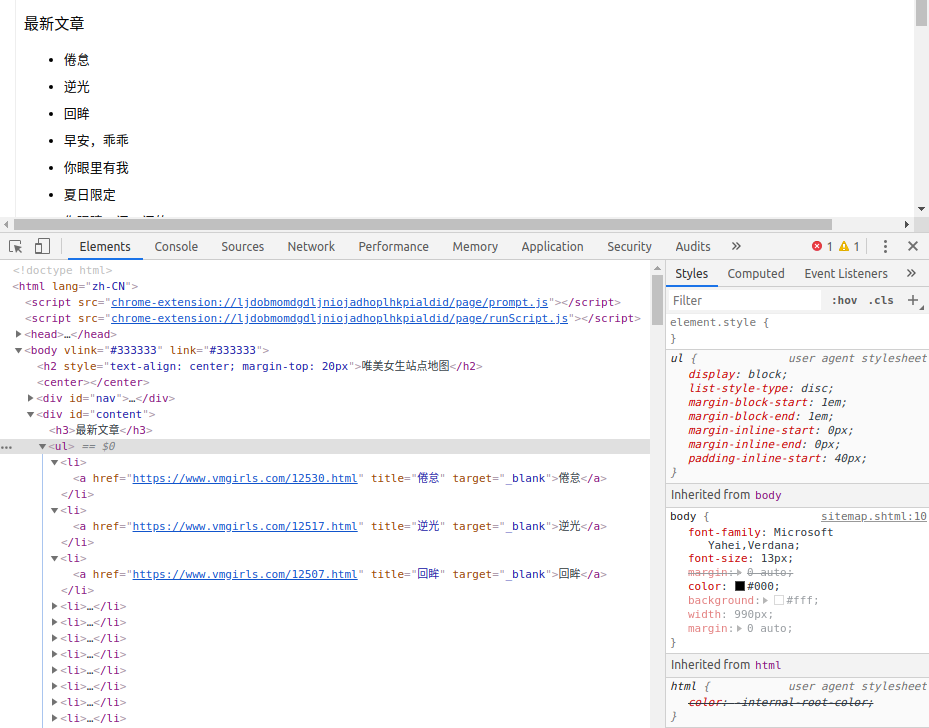
使用wget获取该网页,截取其中一段列表信息如下:
<h2 style="text-align: center; margin-top: 20px">唯美女生站点地图</h2>
<center></center>
<div id="nav">
<a href="https://www.vmgirls.com/"><strong>唯美女生</strong></a> » <a href="https://www.vmgirls.com/sitemap.shtml">站点地图</a>
</div>
<div id="content">
<h3>最新文章</h3>
<ul>
<li><a href="https://www.vmgirls.com/12530.html" title="倦怠" target="_blank">倦怠</a></li>
<li><a href="https://www.vmgirls.com/12517.html" title="逆光" target="_blank">逆光</a></li>
<li><a href="https://www.vmgirls.com/12507.html" title="回眸" target="_blank">回眸</a></li>
<li><a href="https://www.vmgirls.com/12487.html" title="早安,乖乖" target="_blank">早安,乖乖</a></li>
<li><a href="https://www.vmgirls.com/12477.html" title="你眼里有我" target="_blank">你眼里有我</a></li>
<li><a href="https://www.vmgirls.com/12476.html" title="夏日限定" target="_blank">夏日限定</a></li>
<li><a href="https://www.vmgirls.com/12419.html" title="你眼睛一闪一闪的" target="_blank">你眼睛一闪一闪的</a></li>
<li><a href="https://www.vmgirls.com/12405.html" title="夏天你的甜" target="_blank">夏天你的甜</a></li>
<li><a href="https://www.vmgirls.com/12386.html" title="无尽夏" target="_blank">无尽夏</a></li>
<li><a href="https://www.vmgirls.com/12353.html" title="Halcyon" target="_blank">Halcyon</a></li>
<li><a href="https://www.vmgirls.com/12333.html" title="少女情怀" target="_blank">少女情怀</a></li>
从上图可以看出,网页网址以<li>列表形式存储,网页解析时使用以下xpath表达式即可获取到所有的网址和标题。
# example:
# <li><a href="https://www.vmgirls.com/12419.html" title="你眼睛一闪一闪的" target="_blank">你眼睛一闪一闪的</a></li>
urls = response.xpath('//*[@id="content"][1]/ul/li/a/@href').extract()
titles = response.xpath('//*[@id="content"][1]/ul/li/a/text()').extract()
据此,我们便拿到了所有页面的网址和标题,下面针对单个主题页面进行解析。
单个主题页面
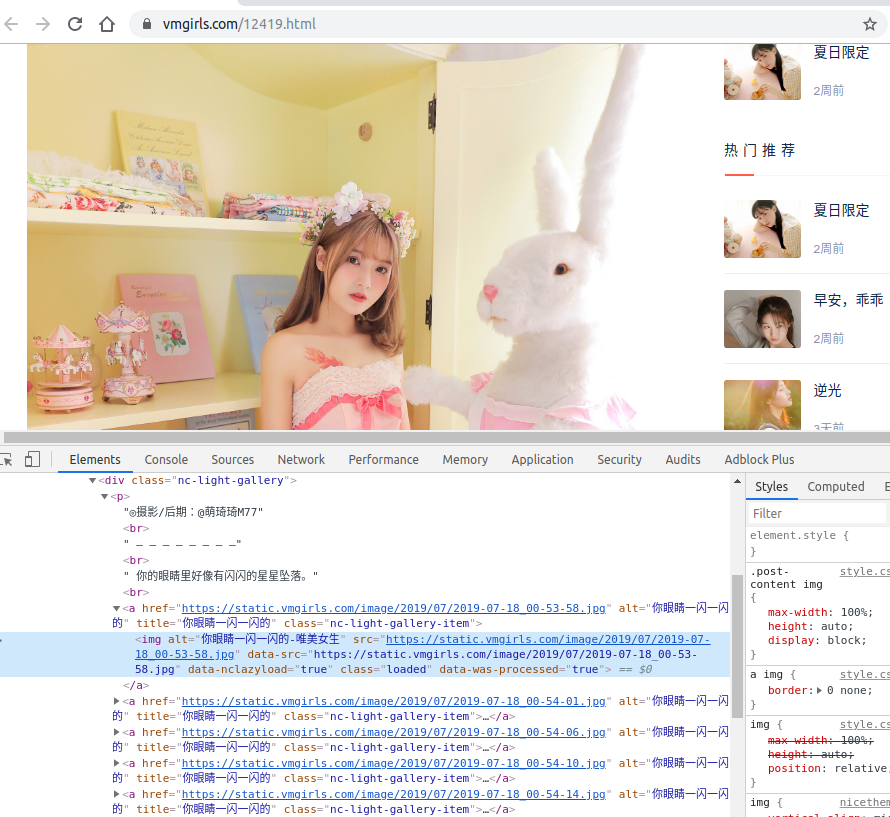
针对单个主题页面,使用Chrome调试工具可以看到图片链接的DOM结构,但是要注意的是,调试工具看到的和实际wget获取到的不太一样,我猜测是在浏览器上显示时执行了某些额外的JS脚本。不管怎么样,当然是要以爬取后的实际数据为准,如下信息所示,img标签的src属性与上图中的不一样,所以我们在解析时不能使用这个属性,但是data-src则是相同的。
<div class="post-content">
<div class="nc-light-gallery">
<p>◎摄影/后期:@萌琦琦M77<br> – – – – – – – –<br> 你的眼睛里好像有闪闪的星星坠落。<br>
<a href="https://static.vmgirls.com/image/2019/07/2019-07-18_00-53-58.jpg" alt="你眼睛一闪一闪的" title="你眼睛一闪一闪的"><img alt="你眼睛一闪一闪的-唯美女生" src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-src="https://static.vmgirls.com/image/2019/07/2019-07-18_00-53-58.jpg" data-nclazyload="true"></a>
<a href="https://static.vmgirls.com/image/2019/07/2019-07-18_00-54-01.jpg" alt="你眼睛一闪一闪的" title="你眼睛一闪一闪的"><img alt="你眼睛一闪一闪的-唯美女生" src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-src="https://static.vmgirls.com/image/2019/07/2019-07-18_00-54-01.jpg" data-nclazyload="true"></a>
由上面的分析可以确定出以下解析方式,以获取到当前页面所有图片的下载链接。
urls = response.xpath('//*[@class="post-content"]//img/@data-src').extract()
至此,单个页面的解析思路也清楚了,之后通过Scrapy的ImagesPipeline即可完成图片下载。
爬虫的代码实现
创建scrapy项目
$ scrapy startproject vmgirls
$ cd vmgirls
$ scrapy genspider vmgirl www.vmgirls.com
$ tree
.
├── scrapy.cfg
└── vmgirl
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── vmgirl.py
全局配置
编辑settings.py
BOT_NAME = 'vmgirls'
SPIDER_MODULES = ['vmgirls.spiders']
NEWSPIDER_MODULE = 'vmgirls.spiders'
import os
USER_DIR = os.path.expanduser('~')
USER_DATA_DIR = os.path.join(USER_DIR, 'Pictures/python/vmgirls')
IMAGES_STORE = USER_DATA_DIR
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'vmgirls.pipelines.VmgirlsPipeline': 300,
'vmgirls.pipelines.VmgirlsImagesPipeline': 400
}
如上代码所示,全局配置文件主要定义了文件存储路径IMAGES_STORE, 禁止遵守robots.txt, 启用两个Pipeline并设置其优先级。
定义Item
接下来定义两个Item类,VmgirlsItem用于存储主题页面的网址及其标题,VmgirlsImagesItem用于存储单个主题页面内所有图片的地址和主题的标题。这两个类的title内容是一致的。
from scrapy.item import Item
from scrapy.item import Field
class VmgirlsItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = Field()
title = Field()
pass
class VmgirlsImagesItem(Item):
image_urls = Field()
title = Field()
pass
编写爬虫
爬虫当然是最关键的一步,爬取思路与开始提及的站点分析思路一致,先爬取站点地图,然后在解析函数parse中获取所有主题页面的网址和标题,并通过VmgirlsItem提交到项目管道;与此同时,将爬取到的主题页面提交给引擎,由引擎把需求转给调度器和下载器;这一步爬取的结果由新的解析函数parse_page处理。
解析函数parse_page会将每个主题页面的图片链接和标题提取出来,然后提交给项目管道,由pipeline部分完成图片下载操作。
import scrapy
from vmgirls.items import VmgirlsItem
from vmgirls.items import VmgirlsImagesItem
from scrapy.http import Request
from scrapy.utils.project import get_project_settings
import os
class VmgirlSpider(scrapy.Spider):
name = 'vmgirl'
allowed_domains = ['vmgirls.com']
start_urls = ['https://www.vmgirls.com/sitemap.shtml/']
def __init__(self):
settings = get_project_settings()
self.user_data_dir = settings.get('USER_DATA_DIR')
def parse(self, response):
'''Parse sitemap'''
urls = response.xpath('//*[@id="content"][1]/ul/li/a/@href').extract()
titles = response.xpath('//*[@id="content"][1]/ul/li/a/text()').extract()
item = VmgirlsItem()
item['theme_urls'] = urls
item['theme_titles'] = titles
yield item
for url, title in zip(urls, titles):
save_path = os.path.join(self.user_data_dir, title)
if not os.path.isdir(save_path):
os.makedirs(save_path)
yield Request(url, meta={'title': title}, callback=self.parse_page)
def parse_page(self, response):
'''Parse each page of girls'''
urls = response.xpath('//*[@class="post-content"]//img/@data-src').extract()
item = VmgirlsImagesItem()
item['image_urls'] = urls
item['title'] = response.meta['title']
yield item
编写Pipeline
爬虫爬取的信息最终通过项目管道进行持久化处理或者完成相应的资源下载任务,从之前的配置文件我们也能知道,我们需要两个pipeline类,一个处理VmgirlsItem,另一个处理VmgirlsImagesPipeline,下面逐一介绍。
from scrapy.exporters import JsonLinesItemExporter
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.http import Request
from vmgirls.items import VmgirlsItem
from vmgirls.items import VmgirlsImagesItem
import os
class VmgirlsPipeline(object):
'''Pipeline for every url of one theme, save theme info to json file'''
def __init__(self, user_data_dir):
'''Open file to save the exported Items'''
self.user_data_dir = user_data_dir
if not os.path.isdir(self.user_data_dir):
os.makedirs(self.user_data_dir)
@classmethod
def from_crawler(cls, crawler):
'''Get user dir from global settings.py'''
settings = crawler.settings
return cls(settings.get('USER_DATA_DIR'))
def process_item(self, item, spider):
'''Save item info to loacl file'''
if isinstance(item, VmgirlsItem):
self.girls_info = open(
os.path.join(self.user_data_dir, 'vmgirls.json'), 'w+b')
self.girls_exporter = JsonLinesItemExporter(
self.girls_info, encoding='utf-8', indent=4)
self.girls_exporter.start_exporting()
for url, title in zip(item['theme_urls'], item['theme_titles']):
single_item = {'theme_url':url, 'title':title}
self.girls_exporter.export_item(single_item)
self.girls_exporter.finish_exporting()
self.girls_info.close()
return item
第一个pipeline类将站点地图的信息以json格式存储到文件vmgirls.json中。这里用到了JsonLinesItemExporter,该类可以将一个个dict数据以单行形式转化成json格式。
class VmgirlsImagesPipeline(ImagesPipeline):
'''Get images from one theme'''
def get_media_requests(self, item, info):
if isinstance(item, VmgirlsImagesItem):
for image_url in item['image_urls']:
yield Request(image_url, meta={'item': item})
def file_path(self, request, response=None, info=None):
'''Set image dir to IMAGES_STORE/title/base_url'''
url = request.url
item = request.meta['item']
path = os.path.join(item['title'], url.split('/')[-1])
return path
def item_completed(self, results, item, info):
if isinstance(item, VmgirlsImagesItem):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
第二个pipeline类继承于ImagesPipeline,这是一个专门用于图片下载的管道类,配置文件中的IMAGES_STORE正是用于指定该类下载图片后的存放路径。
我们这里重写了三个函数:
get_media_requests获取某主题页面的所有图片链接,使用Request进行下载file_path为了将不同主题的图片存储在不同的文件夹,需要修改存储路径item_completed当图片下载完成后,进入该函数,如果没有下载到图片则提示该Item不包含图片
可以注意到,两个管道类在处理item前都有通过isinstance函数判断当前的pipeline属于哪个类的实例,这是为了保证一个管道类只处理对应的管道数据。因为默认情况下,爬虫提交出来的所有item都会根据pipeline的优先级依次经过两个管道,但我们实际只需要每个item经过对应的管道即可,所以使用isinstance进行判断是非常有必要的,既可以提高处理效率,又可以避免过多无效log对调试过程产生的干扰。
爬取结果
为了方便爬取,可以使用以下的代码段作为爬虫的入口。
from scrapy import cmdline
cmdline.execute('scrapy crawl vmgirl'.split())
执行后可以看到爬虫到的图片数据如下:
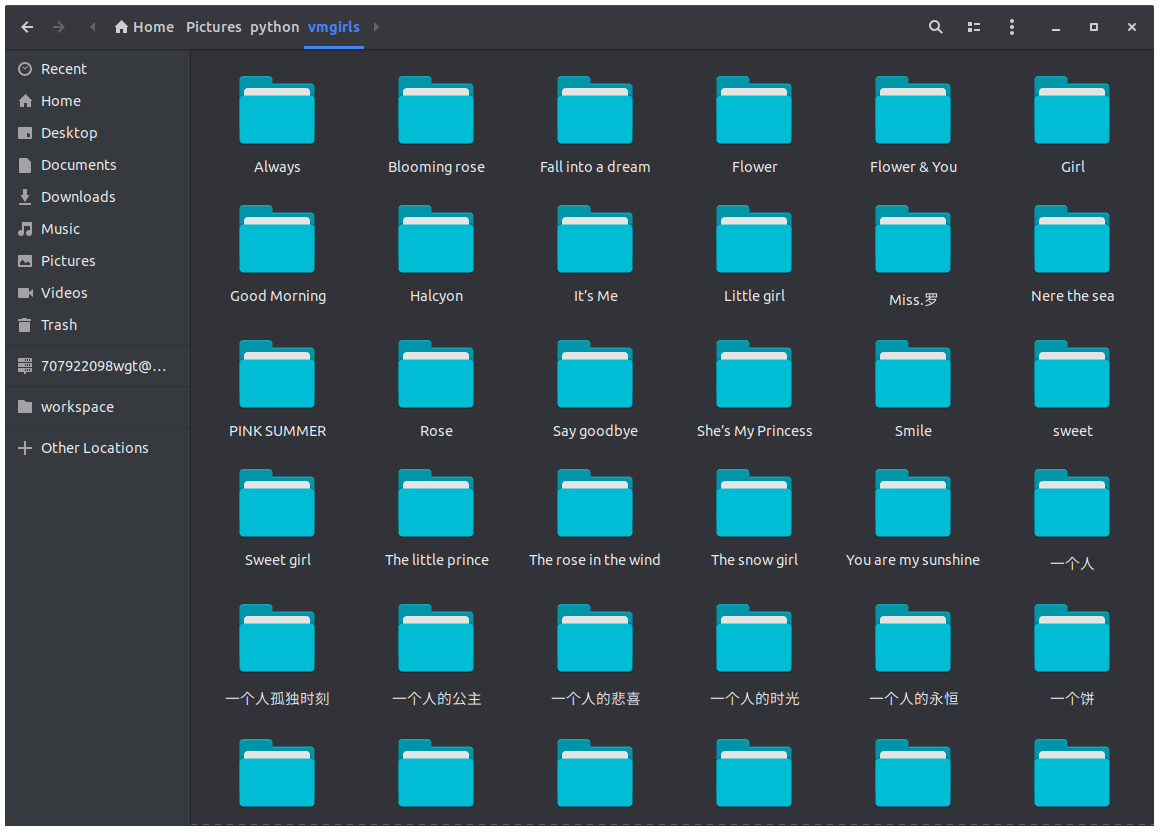
代码已托管至开源项目litreily/capturer, 欢迎Star和交流。
版权声明:本博客所有文章除特殊声明外,均采用 CC BY-NC 4.0 许可协议。转载请注明出处 litreily的博客!