Python网络爬虫2 - 爬取新浪微博用户图片
其实,新浪微博用户图片爬虫是我学习python以来写的第一个爬虫,只不过当时懒,后来爬完Lofter后觉得有必要总结一下,所以就有了第一篇爬虫博客。现在暂时闲下来了,准备把新浪的这个也补上。
言归正传,既然选择爬新浪微博,那当然是有需求的,这也是学习的主要动力之一,没错,就是美图。sina用户多数微博都是包含图片的,而且是组图居多,单个图片的较少。
为了避免侵权,本文以本人微博litreily为例说明整个爬取过程,虽然图片较少,质量较低,但爬取方案是绝对ok的,使用时只要换个用户ID就可以了。
分析sina站点
获取用户ID
在爬取前,我们需要知道的是每个用户都有一个用户名,而一个用户名又对应一个唯一的整型数字ID,类似于学生的学号,本人的是2657006573。至于怎么根据用户名去获取ID,有以下两种方法:
- 进入待爬取用户主页,在浏览器网址栏中即可看到一串数据,那就是用户ID
Ctrl-U查看待爬取用户的源码,搜索"uid,注意是双引号
其实是可以在已知用户名的情况下通过爬虫自动获取到uid的,但是我当时初学python,并没有考虑充分,所以后面的源码是以用户ID作为输入参数的。
图片存储参数解析
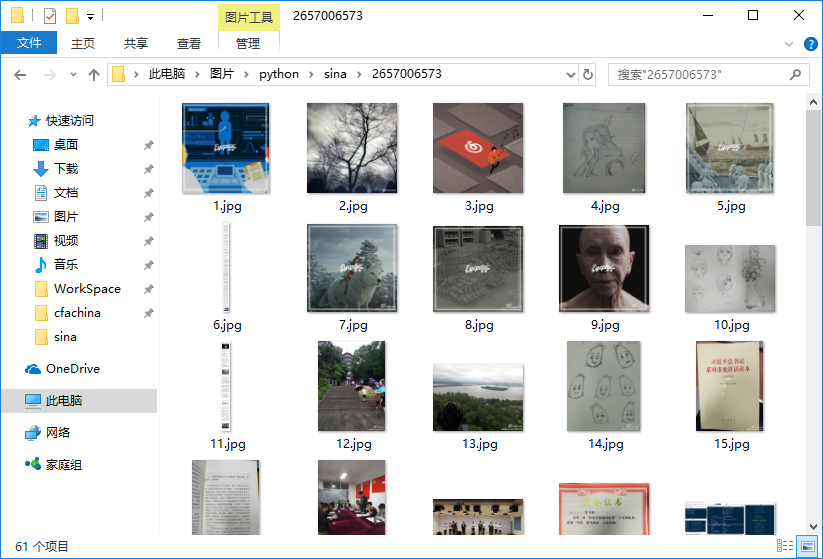
用户所有的图片都被存放至这样的路径下,真的是所有图片哦!!!
https://weibo.cn/{uid}/profile?filter={filter_type}&page={page_num}
# example
https://weibo.cn/2657006573/profile?filter=0&page=1
uid: 2657006573
filter_type: 0
page_num: 1注意,是weibo.cn而不是weibo.com,至于我是怎么找到这个页面的,说实话,我也忘了。。。
链接中包含3个参数,uid, filter_mode 以及 page_num。其中,uid就是前面提及的用户ID,page_num也很好理解,就是分页的当前页数,从1开始增加,那么,这个filter_mode是什么呢?
不着急,我们先来看看页面↓
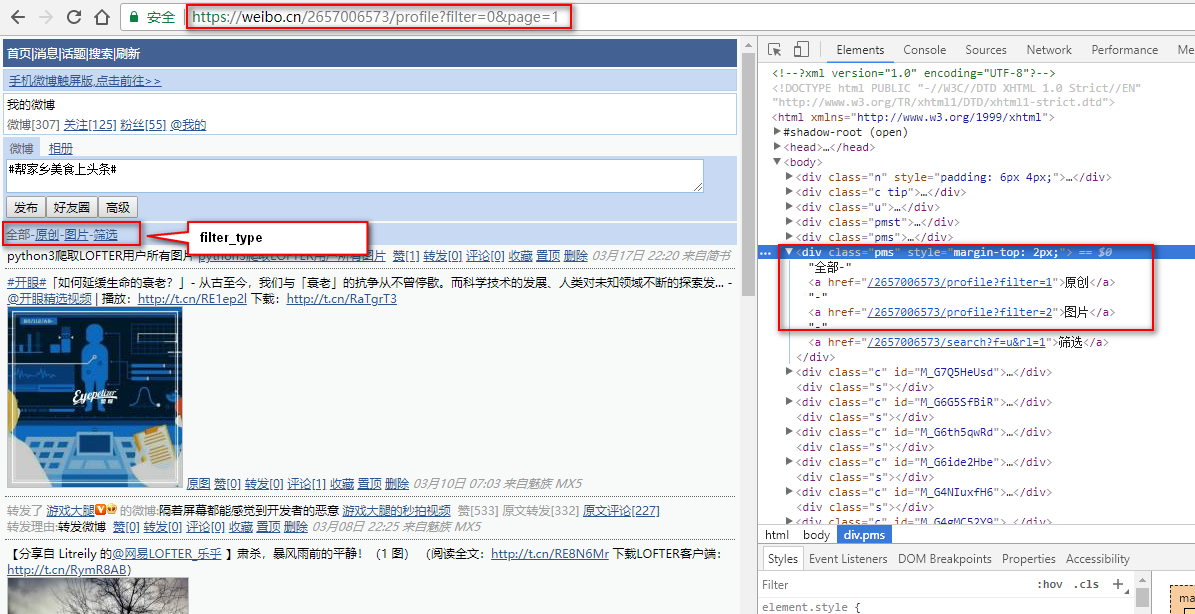
可以看到,滤波类型filter_mode指的就是筛选条件,一共三个:
- filter=0 全部微博(包含纯文本微博,转载微博)
- filter=1 原创微博(包含纯文本微博)
- filter=2 图片微博(必须含有图片,包含转载)
我通常会选择原创,因为我并不希望爬取结果中包含转载微博中的图片。当然,大家依照自己的需要选择即可。
图链解析
好了,参数来源都知道了,我们回过头看看这个网页。页面是不是感觉就是个空架子?毫无css痕迹,没关系,新浪本来就没打算把这个页面主动呈现给用户。但对于爬虫而言,这却是极好的,为什么这么说?原因如下:
- 图片齐全,没有遗漏,就是个可视化的数据库
- 样式少,页面简单,省流量,爬取快
- 静态网页,分页存储,所见即所得
- 源码包含了所有微博的首图和组图链接
这样的网页用来练手再合适不过。但要注意的是上面第4点,什么是首图和组图链接呢,很好理解。每篇博客可能包含多张图片,那就是组图,但该页面只显示博客的第一张图片,即所谓的首图,组图链接指向的是存储着该组图所有图片的网址。
由于本人微博没组图,所以此处以刘亦菲微博为例,说明单图及组图的图链格式
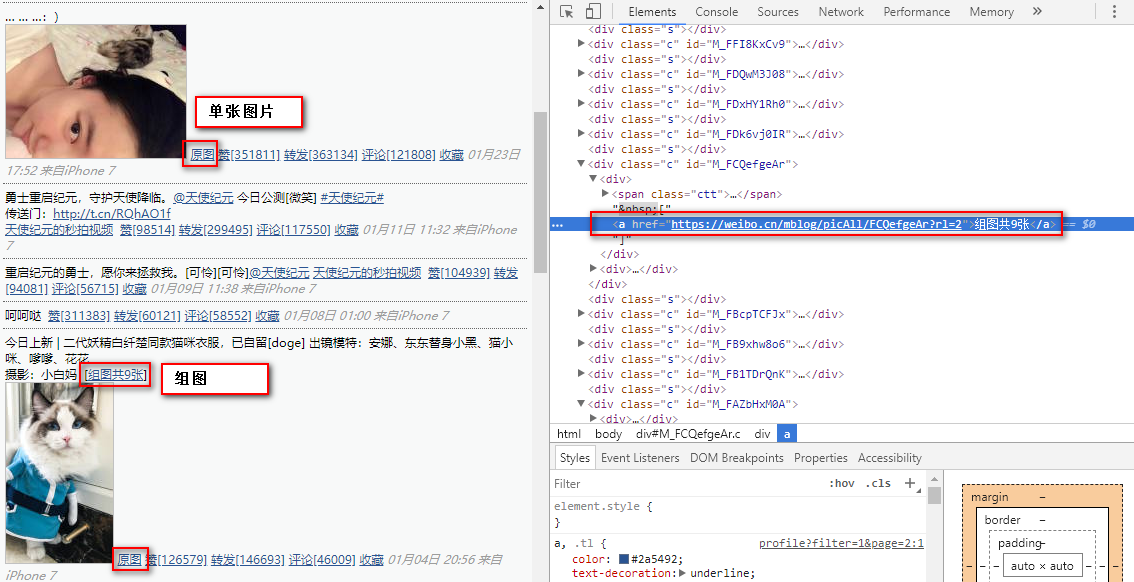
图中的上面一篇微博只有一张图片,可以轻易获取到原图链接,注意是原图,因为我们在页面能看到的是缩略图,但要爬取的当然是原图啦。
图中下面的微博包含组图,在图片右侧的Chrome开发工具可以看到组图链接。
https://weibo.cn/mblog/picAll/FCQefgeAr?rl=2
打开组图链接,可以看到图片如下图所示:
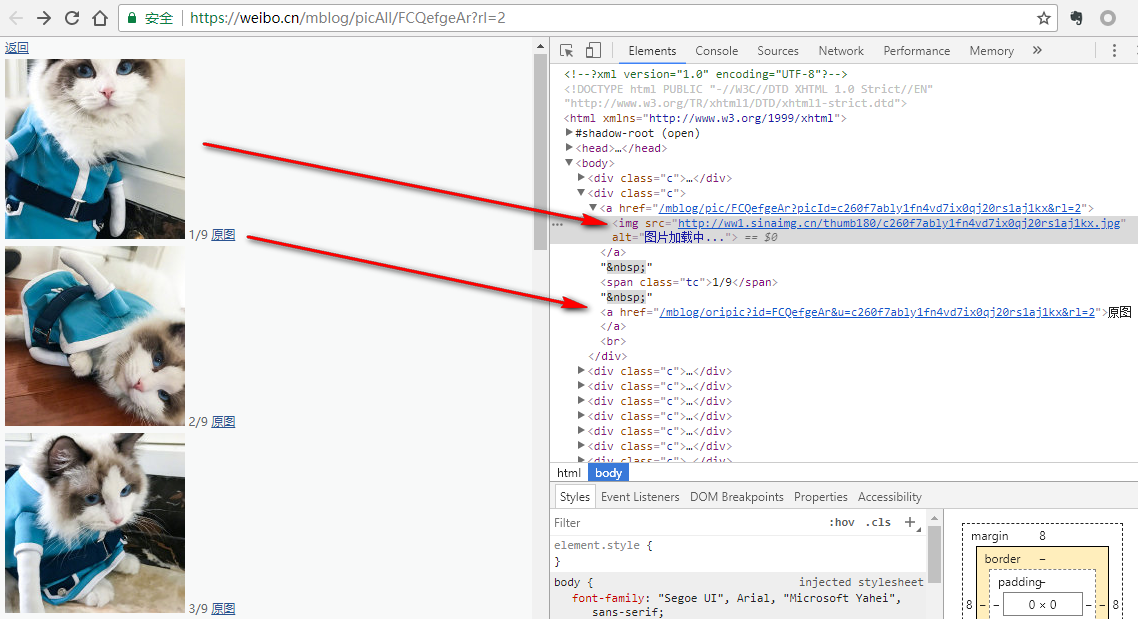
可以看到缩略图链接以及原图链接,然后我们点击原图看一下。

可以发现,弹出页面的链接与上图显示的不同,但与上图中的缩略图链接极为相似。它们分别是:
- 缩略图:http://ww1.sinaimg.cn/thumb180/c260f7ably1fn4vd7ix0qj20rs1aj1kx.jpg
- 原图:http://wx1.sinaimg.cn/large/c260f7ably1fn4vd7ix0qj20rs1aj1kx.jpg
可以看出,只是一个thumb180和large的区别。既然发现了规律,那就好办多了,我们只要知道缩略图的网址,就可以将域名后的第一级子域名替换成large就可以了,而不用获取原图链接再跳转一次。
而且,多次尝试可以发现组图链接及缩略图链接满足正则表达式:
# 1. 组图链接:
imglist_reg = r'href="(https://weibo.cn/mblog/picAll/.{9}\?rl=2)"'
# 2. 缩略图
img_reg = r'src="(http://w.{2}\.sinaimg.cn/(.{6,8})/.{32,33}.(jpg|gif))"'到此,新浪微博的解析过程就结束了,图链的格式以及获取方式也都清楚了。下面就可以设计方案进行爬取了。
确定爬取方案
根据解析结果,很容易制定出以下爬取方案:
- 给定微博用户名
litreily - 进入待爬取用户主页,即可从网址中获取
uid: 2657006573 - 获取本人登录微博后的
cookies(请求报文需要用到cookies) - 逐一爬取https://weibo.cn/2657006573/profile?filter=0&page={1,2,3,...}
- 解析每一页的源码,获取单图链接及组图链接,
- 单图:直接获取该图缩略图链接;
- 组图:爬取组图链接,循环获取组图页面所有图片的缩略图链接
- 循环将第5步获取到的图链替换为原图链接,并下载至本地
- 重复第4-6步,直至没有图片
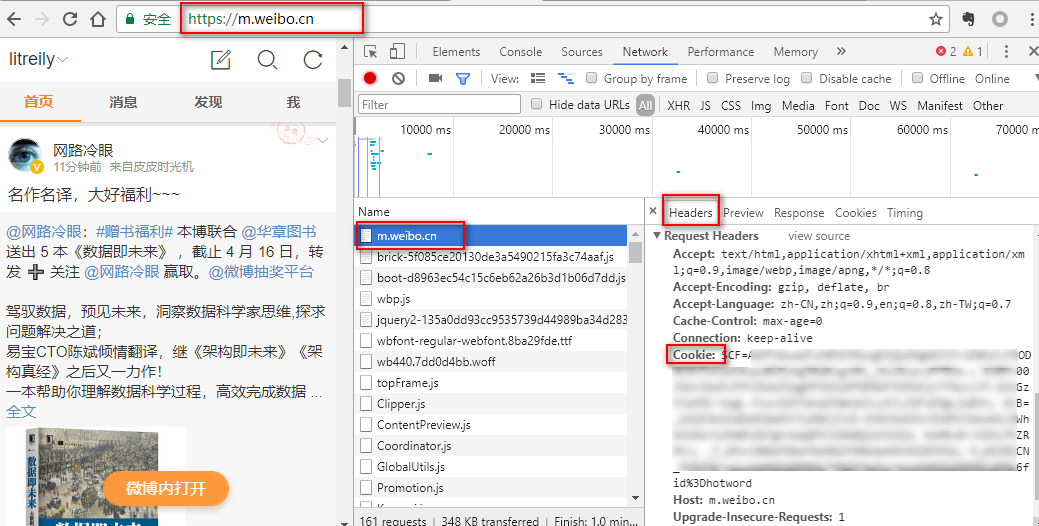
获取cookies
针对以上方案,其中有几个重点内容,其一就是cookies的获取,我暂时还没学怎么自动获取cookies,所以目前是登录微博后手动获取的。
下载网页
下载网页用的是python3自带的urllib库,当时没学requests,以后可能也很少用urllib了。
def _get_html(url, headers):
try:
req = urllib.request.Request(url, headers = headers)
page = urllib.request.urlopen(req)
html = page.read().decode('UTF-8')
except Exception as e:
print("get %s failed" % url)
return None
return html获取存储路径
由于我是在win10下编写的代码,但是个人比较喜欢用bash,所以图片的存储路径有以下两种格式,_get_path函数会自动判断当前操作系统的类型,然后选择相应的路径。
def _get_path(uid):
path = {
'Windows': 'D:/litreily/Pictures/python/sina/' + uid,
'Linux': '/mnt/d/litreily/Pictures/python/sina/' + uid
}.get(platform.system())
if not os.path.isdir(path):
os.makedirs(path)
return path幸好windows是兼容linux系统的斜杠符号的,不然程序中的相对路径替换还挺麻烦。
下载图片
由于选用的urllib库,所以下载图片就使用urllib.request.urlretrieve了
# image url of one page is saved in imgurls
for img in imgurls:
imgurl = img[0].replace(img[1], 'large')
num_imgs += 1
try:
urllib.request.urlretrieve(imgurl, '{}/{}.{}'.format(path, num_imgs, img[2]))
# display the raw url of images
print('\t%d\t%s' % (num_imgs, imgurl))
except Exception as e:
print(str(e))
print('\t%d\t%s failed' % (num_imgs, imgurl))源码
其它细节详见源码
#!/usr/bin/python3
# -*- coding:utf-8 -*-
# author: litreily
# date: 2018.02.05
"""Capture pictures from sina-weibo with user_id."""
import re
import os
import platform
import urllib
import urllib.request
from bs4 import BeautifulSoup
def _get_path(uid):
path = {
'Windows': 'D:/litreily/Pictures/python/sina/' + uid,
'Linux': '/mnt/d/litreily/Pictures/python/sina/' + uid
}.get(platform.system())
if not os.path.isdir(path):
os.makedirs(path)
return path
def _get_html(url, headers):
try:
req = urllib.request.Request(url, headers = headers)
page = urllib.request.urlopen(req)
html = page.read().decode('UTF-8')
except Exception as e:
print("get %s failed" % url)
return None
return html
def _capture_images(uid, headers, path):
filter_mode = 1 # 0-all 1-original 2-pictures
num_pages = 1
num_blogs = 0
num_imgs = 0
# regular expression of imgList and img
imglist_reg = r'href="(https://weibo.cn/mblog/picAll/.{9}\?rl=2)"'
imglist_pattern = re.compile(imglist_reg)
img_reg = r'src="(http://w.{2}\.sinaimg.cn/(.{6,8})/.{32,33}.(jpg|gif))"'
img_pattern = re.compile(img_reg)
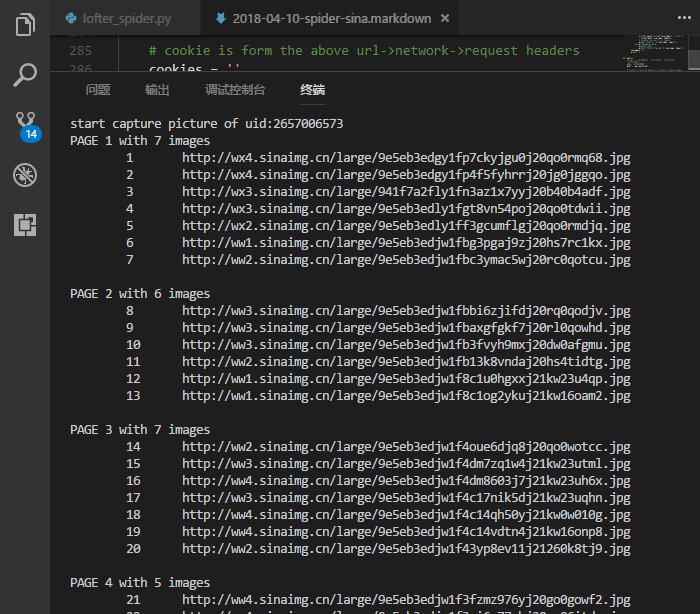
print('start capture picture of uid:' + uid)
while True:
url = 'https://weibo.cn/%s/profile?filter=%s&page=%d' % (uid, filter_mode, num_pages)
# 1. get html of each page url
html = _get_html(url, headers)
# 2. parse the html and find all the imgList Url of each page
soup = BeautifulSoup(html, "lxml")
# <div class="c" id="M_G4gb5pY8t"><div>
blogs = soup.body.find_all(attrs={'id':re.compile(r'^M_')}, recursive=False)
num_blogs += len(blogs)
imgurls = []
for blog in blogs:
blog = str(blog)
imglist_url = imglist_pattern.findall(blog)
if not imglist_url:
# 2.1 get img-url from blog that have only one pic
imgurls += img_pattern.findall(blog)
else:
# 2.2 get img-urls from blog that have group pics
html = _get_html(imglist_url[0], headers)
imgurls += img_pattern.findall(html)
if not imgurls:
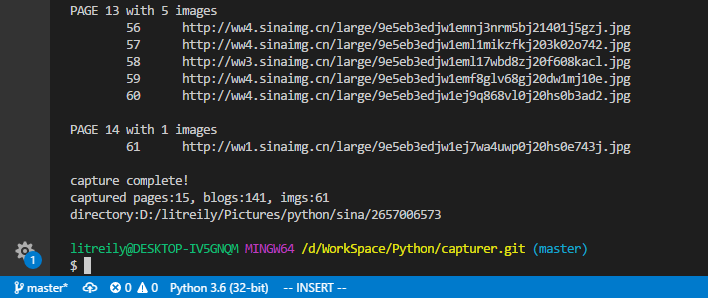
print('capture complete!')
print('captured pages:%d, blogs:%d, imgs:%d' % (num_pages, num_blogs, num_imgs))
print('directory:' + path)
break
# 3. download all the imgs from each imgList
print('PAGE %d with %d images' % (num_pages, len(imgurls)))
for img in imgurls:
imgurl = img[0].replace(img[1], 'large')
num_imgs += 1
try:
urllib.request.urlretrieve(imgurl, '{}/{}.{}'.format(path, num_imgs, img[2]))
# display the raw url of images
print('\t%d\t%s' % (num_imgs, imgurl))
except Exception as e:
print(str(e))
print('\t%d\t%s failed' % (num_imgs, imgurl))
num_pages += 1
print('')
def main():
# uids = ['2657006573','2173752092','3261134763','2174219060']
uid = '2657006573'
path = _get_path(uid)
# cookie is form the above url->network->request headers
cookies = ''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Cookie': cookies}
# capture imgs from sina
_capture_images(uid, headers, path)
if __name__ == '__main__':
main()
使用时记得修改main函数中的cookies和uid!
爬取测试