
Python之markdown转Chrome收藏夹
网上可以搜到很多chrome收藏夹转markdown文档的方法,却鲜有markdown文档转为Chrome收藏夹的方法,不过这种需求也确实不多。我之所以用到,是因为平常会用markdown文档收集一些网站,现在想要转换为Chrome收藏夹,方便访问。
思路
要实现这个功能倒也不难,因为Chrome的收藏夹本质上也是一个html文件,只不过有其固定的DOM结构而已,所以我们的实现思路很简单。
- 导出Chrome已有的收藏夹
- 分析导出得到的html文件格式
- 将自己需要转成Chrome收藏夹的markdown按相同格式转换为html文件
- 在chrome中导入生成后的收藏夹
收藏夹的DOM结构
我导出了自己的收藏夹,取出其中一小部分为例进行分析,比较局部是可以反映整体的。
<!DOCTYPE NETSCAPE-Bookmark-file-1>
<!-- This is an automatically generated file.
It will be read and overwritten.
DO NOT EDIT! -->
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=UTF-8">
<TITLE>Bookmarks</TITLE>
<H1>Bookmarks</H1>
<DL><p>
<DT><H3 ADD_DATE="1499940499" LAST_MODIFIED="1573567059" PERSONAL_TOOLBAR_FOLDER="true">Bookmarks bar</H3>
<DL><p>
<DT><H3 ADD_DATE="1481956366" LAST_MODIFIED="1565750292">不常用</H3>
<DL><p>
<DT><H3 ADD_DATE="1460906121" LAST_MODIFIED="1582357904">设计</H3>
<DL><p>
<DT><A HREF="https://w3layouts.com/" ADD_DATE="1460906098" ICON="data:image/png;base64,">Free Responsive Mobile Website Templates Designs - w3layouts.com</A>
<DT><A HREF="http://www.hightopo.com/demos/index.html" ADD_DATE="1472525305" ICON="data:image/png;base64,">Hightopo - Everything you need to create cutting-edge 2D and 3D visualization</A>
<DT><A HREF="http://jekyllthemes.org/" ADD_DATE="1459860502">Jekyll Themes</A>
</DL><p>
<DT><H3 ADD_DATE="1468076322" LAST_MODIFIED="1538094516">算法</H3>
<DL><p>
<DT><A HREF="http://www.pythontip.com/acm/problemCategory" ADD_DATE="1468076332" ICON="data:image/png;base64,">各大OJ题目分类</A>
<DT><A HREF="http://www.acmerblog.com/" ADD_DATE="1468075312" ICON="data:image/png;base64,">Acm之家</A>
</DL><p>
<DT><H3 ADD_DATE="1550926992" LAST_MODIFIED="1582961771">图标</H3>
<DL><p>
<DT><A HREF="https://www.emojicopy.com/" ADD_DATE="1550926923" ICON="data:image/png;base64,">EmojiCopy | Simple emoji copy and paste by EmojiOne™</A>
<DT><A HREF="https://www.webfx.com/tools/emoji-cheat-sheet/" ADD_DATE="1582961771" ICON="data:image/png;base64,">🎁 Emoji cheat sheet for GitHub, Basecamp, Slack & more</A>
</DL><p>
<DT><H3 ADD_DATE="1412991964" LAST_MODIFIED="1586250269">论坛</H3>
<DL><p>
<DT><A HREF="https://www.qt.io/" ADD_DATE="1472370392" ICON="data:image/png;base64,">Qt</A>
<DT><A HREF="https://freessl.cn/" ADD_DATE="1566824588" ICON="data:image/png;base64,">FreeSSL首页 - FreeSSL.cn 一个申请免费HTTPS证书的网站</A>
</DL><p>
</DL><p>
<DT><H3 ADD_DATE="1538059196" LAST_MODIFIED="1569229251">wiki</H3>
<DL><p>
<DT><A HREF="https://code.woboq.org/linux/linux/" ADD_DATE="1528874869" ICON="data:image/png;base64,">linux/linux/ Source Tree - Woboq Code Browser</A>
<DT><A HREF="https://www.geeksforgeeks.org/c-programming-language/" ADD_DATE="1569229251">C Programming Language - GeeksforGeeks</A>
</DL><p>
<DT><A HREF="http://translate.google.cn/" ADD_DATE="1446427265" ICON="data:image/png;base64,"></A>
<DT><A HREF="http://www.litreily.top/" ADD_DATE="1481438786" ICON="data:image/png;base64,"></A>
</DL><p>
</DL><p>以上DOM结构中,每条收藏都有一个<A>标签,该标签有一个base64值对应的是base64编码后的图标,也就是每个收藏的图标,这个不是必须的,为了方便阅读,我将其删除了,并不影响。
如果使用上面的html文件导入chrome的话,是下面这样的。
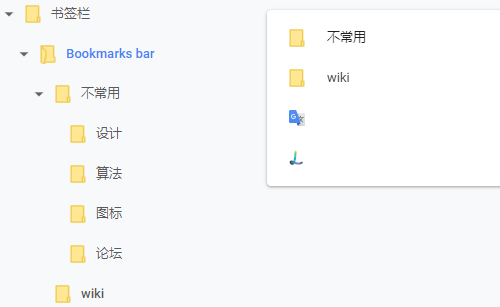
注意其中两个收藏(谷歌翻译和我的博客主页)没有显示描述信息,这个在chrome中是允许的,因为根据图标就能知道这是什么站点。
好啦,对比DOM结构和在收藏夹的展示,不难发现规律:
- 所有收藏夹中的文件夹无论在哪一个层级,都对应DOM中的一个
<DT><H3>标签 <H3>标签包含属性:ADD_DATE,LAST_MODIFIED- 收藏夹中文件夹可以嵌套
- 每个
<DT><H3>标签都紧随着一组<DL><p> - 每个
<DL><p>里都包含一个收藏列表 - 每条收藏都以
<DT><A>标签组合,对应收藏的链接 <A>标签包含属性:HREF,ADD_DATE,ICON
到此就完成了对收藏夹的分析,下面就可以按照这个格式将markdown转换成相应的html
markdown转html
markdown文档格式很简单,同样举例说明,下面是用markdown格式编写的收藏夹。
# 收藏夹(Favorites)
## 常用
- [谷歌翻译](http://translate.google.cn/)
- [litreily](http://www.litreily.top/)
- [Notes](https://litreily.gitbook.io/notes/content/)
- [smslit](http://www.smslit.top/)
- [github](https://github.com/)
- [coding](https://coding.net/user)
## 论坛(forum)
- [Coding 博客](https://blog.coding.net/)
- [图灵社区](http://www.ituring.com.cn/)
- [电子发烧友](http://www.elecfans.com/)
## 编程(Programming)
### 算法(Algorithm)
- [Acm之家](http://www.acmerblog.com/)
- [各大OJ题目分类](http://www.pythontip.com/acm/problemCategory)
### linux
- [linux - Elixir - Free Electrons](http://elixir.free-electrons.com/linux/latest/source)我们使用Python对其逐行读取处理,处理策略如下:
- 新建html文件favorites.html,添加HTML头部信息
- 获取当前系统时间作为收藏夹中所有的
LAST_MODIFIED和ADD_DATE - 将所有以
#开头的视为文件夹,添加<DT><H3>标签,设置时间戳和文件夹名称 - 在
<DT><H3>标签后紧跟<DL><p>标签 - 将所有链接替换为
<DT><A>格式,这个需要用到python的正则匹配和替换,非常方便 - 在合适的位置添加
</DL><p>标签,用以封装<DL><p>
使用该策略编写的Python脚本如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# convert markdown to chrome bookmarks
# @author: litreily
# @date: 2020-04-25
import sys
import time
import re
TIMESTAMP = int(time.time())
HTML_HEAD = """\
<!DOCTYPE NETSCAPE-Bookmark>
<!-- This is an automatically generated file.
It will be read and overwritten.
DO NOT EDIT! -->
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=UTF-8">
<TITLE>Bookmarks</TITLE>
<H1>Bookmarks</H1>
<DL><p>
""".format(TIMESTAMP)
HTML_END = """</DL><p>\n"""
GROUP_HEAD = """\t<DT><H3 ADD_DATE="{ts}" LAST_MODIFIED="{ts}">{title}</H3>
\t<DL><p>
"""
GROUP_END = "\t</DL><p>\n"
MASK = """\t<DT>\
<A HREF="{link}" ADD_DATE="{ts}" ICON="data:image/png;base64,{icon}">{title}</A>
"""
def main(input):
with open(input, 'r') as f:
lists = f.readlines()
# open html file to write into
output = open('favorites.html', 'w')
output.write(HTML_HEAD)
group_re = re.compile(r'^(#+) +(.*)$') # eg. ## network
mask_re = re.compile(r'\[(.*)\]\((.*)\)') # eg. [baidu](https://www.baidu.com)
pre_H_level = 0 # previous Header level, H2 or H3 or ...
for line in lists:
line = line.strip()
m = mask_re.search(line)
if m:
# find link
output.write(MASK.format(link=m.group(2), ts=TIMESTAMP, icon=None, title=m.group(1)))
else:
m = group_re.search(line)
if m:
# find header
cur_H_level = len(m.group(1)) # current Header level
if cur_H_level <= pre_H_level:
for _ in range(pre_H_level - cur_H_level + 1):
output.write(GROUP_END)
pre_H_level = cur_H_level
output.write(GROUP_HEAD.format(ts=TIMESTAMP, title=m.group(2)))
output.write(HTML_END)
if __name__ == "__main__":
if len(sys.argv) < 2:
print('No input files.')
sys.exit(1)
main(sys.argv[1])这个脚本唯一需要注意的一点是:什么时候添加<DL><p>对应的</DL><p>闭合标签?如果在错误位置添加了或者是没添加,都会导致收藏夹嵌套顺序错乱。
对此我的思路是:对比前后两次markdown中读取到的HEADER层级,比如H2对应2,H3对应3. 前一次pre_H_level,当前cur_H_level,如果cur_H_level <= pre_H_level就需要添加,而且添加个数等于前后两数之差加1.
举例说明:
## H2_1
...
### H3 # pre: H2, cur: H3. cur > pre, 不加
...
## H2_2 # pre: H3, cur: H2, cur < pre, 加(3-2+1)=2次
...
## H2_3 # pre: H2, cur: H2, cur = pre, 加(2-2+1)=1次当然,这种做法的前提是markdown符合语法要求。
导入chrome
使用以上脚本将markdown转换为html
./md2bm test.md<!DOCTYPE NETSCAPE-Bookmark>
<!-- This is an automatically generated file.
It will be read and overwritten.
DO NOT EDIT! -->
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=UTF-8">
<TITLE>Bookmarks</TITLE>
<H1>Bookmarks</H1>
<DL><p>
<DT><H3 ADD_DATE="1588501602" LAST_MODIFIED="1588501602">收藏夹(Favorites)</H3>
<DL><p>
<DT><H3 ADD_DATE="1588501602" LAST_MODIFIED="1588501602">常用</H3>
<DL><p>
<DT><A HREF="http://translate.google.cn/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">谷歌翻译</A>
<DT><A HREF="http://www.litreily.top/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">litreily</A>
<DT><A HREF="https://litreily.gitbook.io/notes/content/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">Notes</A>
<DT><A HREF="http://www.smslit.top/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">smslit</A>
<DT><A HREF="https://github.com/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">github</A>
<DT><A HREF="https://coding.net/user" ADD_DATE="1588501602" ICON="data:image/png;base64,None">coding</A>
</DL><p>
<DT><H3 ADD_DATE="1588501602" LAST_MODIFIED="1588501602">论坛(forum)</H3>
<DL><p>
<DT><A HREF="https://blog.coding.net/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">Coding 博客</A>
<DT><A HREF="http://www.ituring.com.cn/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">图灵社区</A>
<DT><A HREF="http://www.elecfans.com/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">电子发烧友</A>
</DL><p>
<DT><H3 ADD_DATE="1588501602" LAST_MODIFIED="1588501602">编程(Programming)</H3>
<DL><p>
<DT><H3 ADD_DATE="1588501602" LAST_MODIFIED="1588501602">算法(Algorithm)</H3>
<DL><p>
<DT><A HREF="http://www.acmerblog.com/" ADD_DATE="1588501602" ICON="data:image/png;base64,None">Acm之家</A>
<DT><A HREF="http://www.pythontip.com/acm/problemCategory" ADD_DATE="1588501602" ICON="data:image/png;base64,None">各大OJ题目分类</A>
</DL><p>
<DT><H3 ADD_DATE="1588501602" LAST_MODIFIED="1588501602">linux</H3>
<DL><p>
<DT><A HREF="http://elixir.free-electrons.com/linux/latest/source" ADD_DATE="1588501602" ICON="data:image/png;base64,None">linux - Elixir - Free Electrons</A>
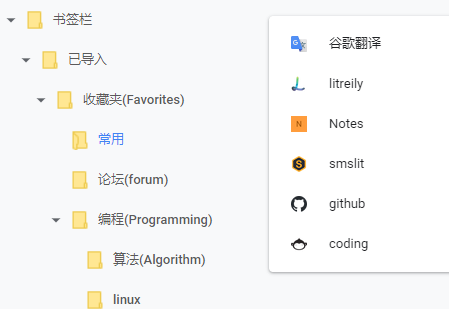
</DL><p>最后导入Chrome看下,Chrome会添加一个新的文件夹已导入,我们可以把子文件夹拖出来就ok了,再看看图标,如果最近有访问过,其实不加icon的base64信息也是可以显示出来的,就算现在没有,以后只要访问过一次就会自动更新,这点倒是有点像交换机的学习机制。
最后
这个脚本也已经更新到了GitHub Litreily/Python-scripts,欢迎有需要的小伙伴们使用。




