
Python网络爬虫8 - 爬取彼岸图网美图
彼岸图网收集了大量美图,是个不错的爬取对象。话不多说,直接上图。
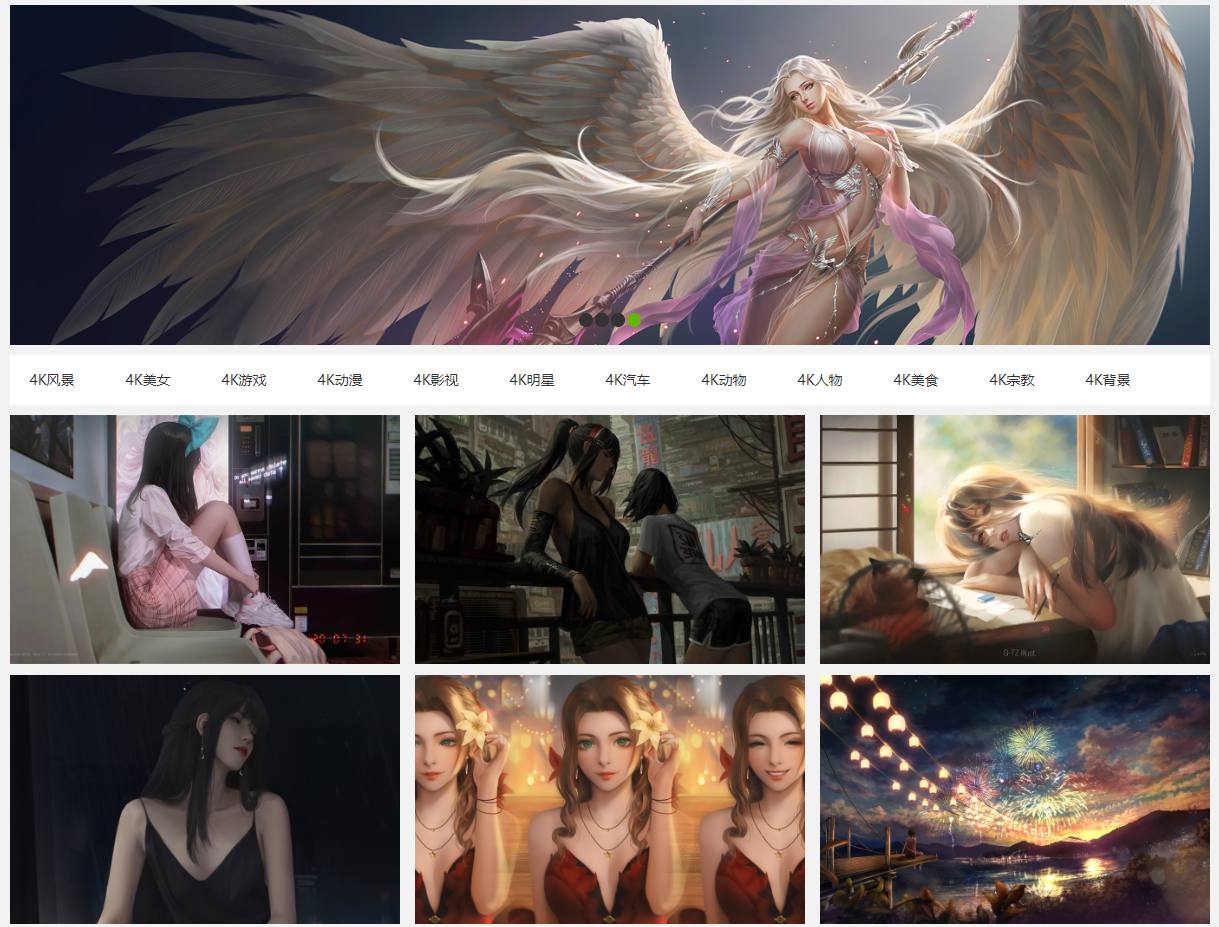
分析站点
分类列表
爬取之前,自然要分析一波,这个站点的框架比较简单,从分类着手,共包含12个分类项。
- 4K人物
- 4K动漫
- 4K动物
- 4K宗教
- 4K影视
- 4K明星
- 4K汽车
- 4K游戏
- 4K美女
- 4K美食
- 4K背景
- 4K风景
名称都含有4K,但是获取原图是需要会员的,所以我这里获取的不是原图,而是详细页展示的大图。首先要获取的当然是分类页面的网址,看下面的DOM.
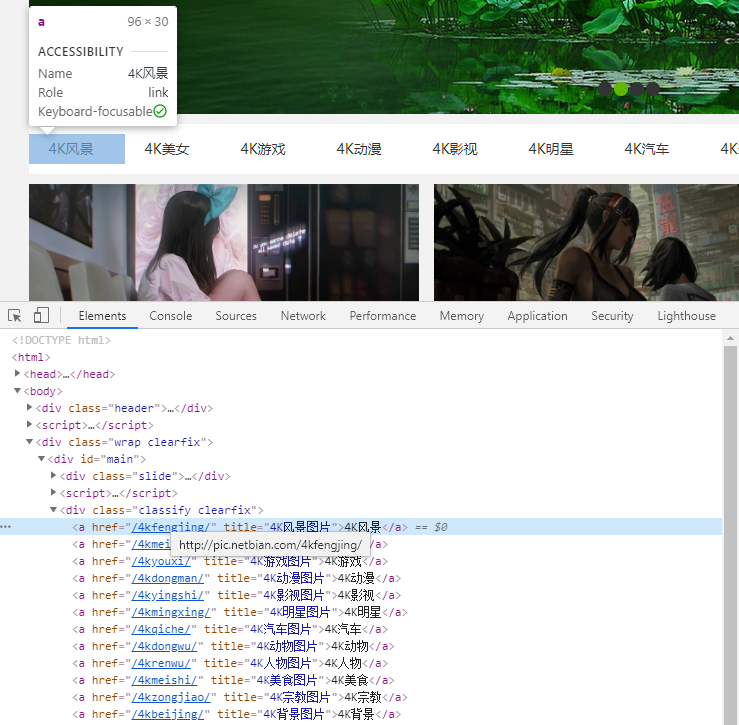
通过xpath //div[contains(@class, "classify")]/a 可以得到分类链接信息,从而可以得到分类名称和网址。
缩略图列表
接下来以4k影视为例,解析每个分类页面,从分类页面可以看到图片的缩略图列表,点击缩略图就能进入详细页面看到大图。
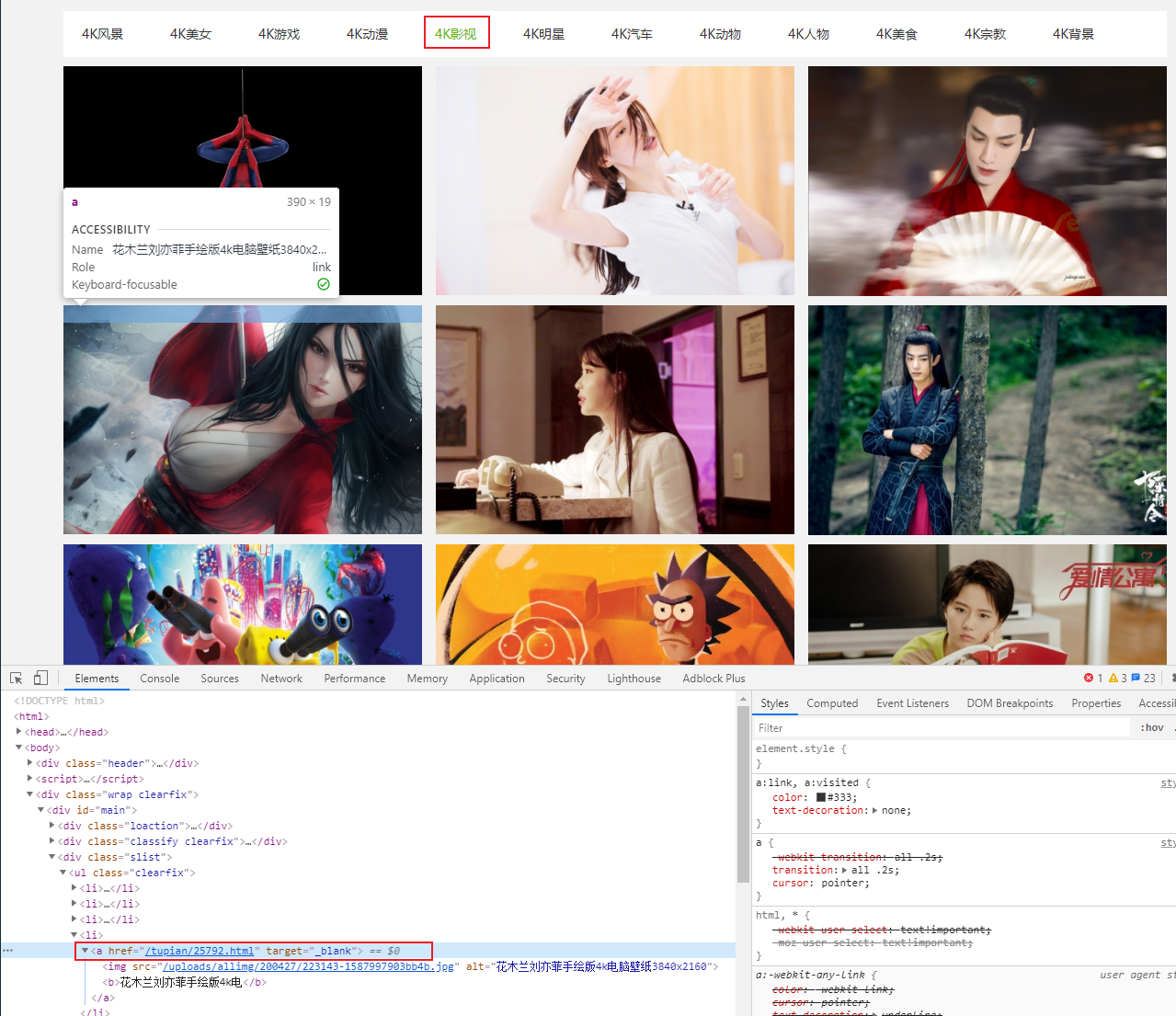
缩略图列表中的图片链接可以通过xpath //div[@class="slist"]//a/@href 获得。
此外,分类页面包含大量图片,是通过分页展示的,分页的页数可以从页面尾部看到。
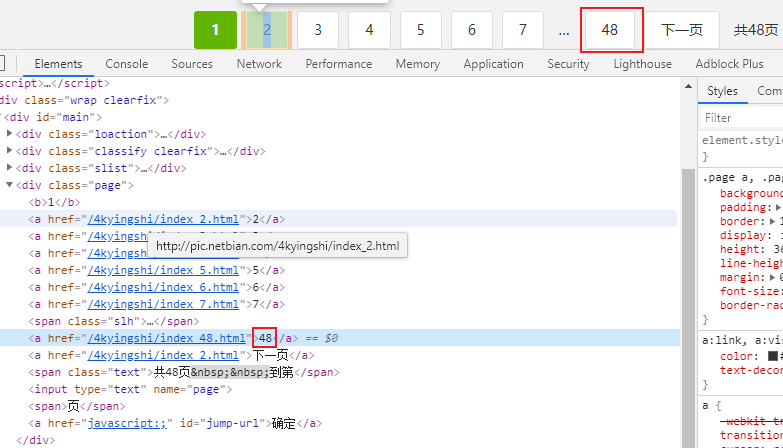
页面数量可以通过xpath //span[@class="slh"]/following-sibling::a[1]/text()获得,也就是...后的同胞元素。
大图页面
最后就是通过缩略图访问的大图页面了,根据大图的id信息,其实际链接可以通过xpath //*[@id="img"]/img/@src获得。
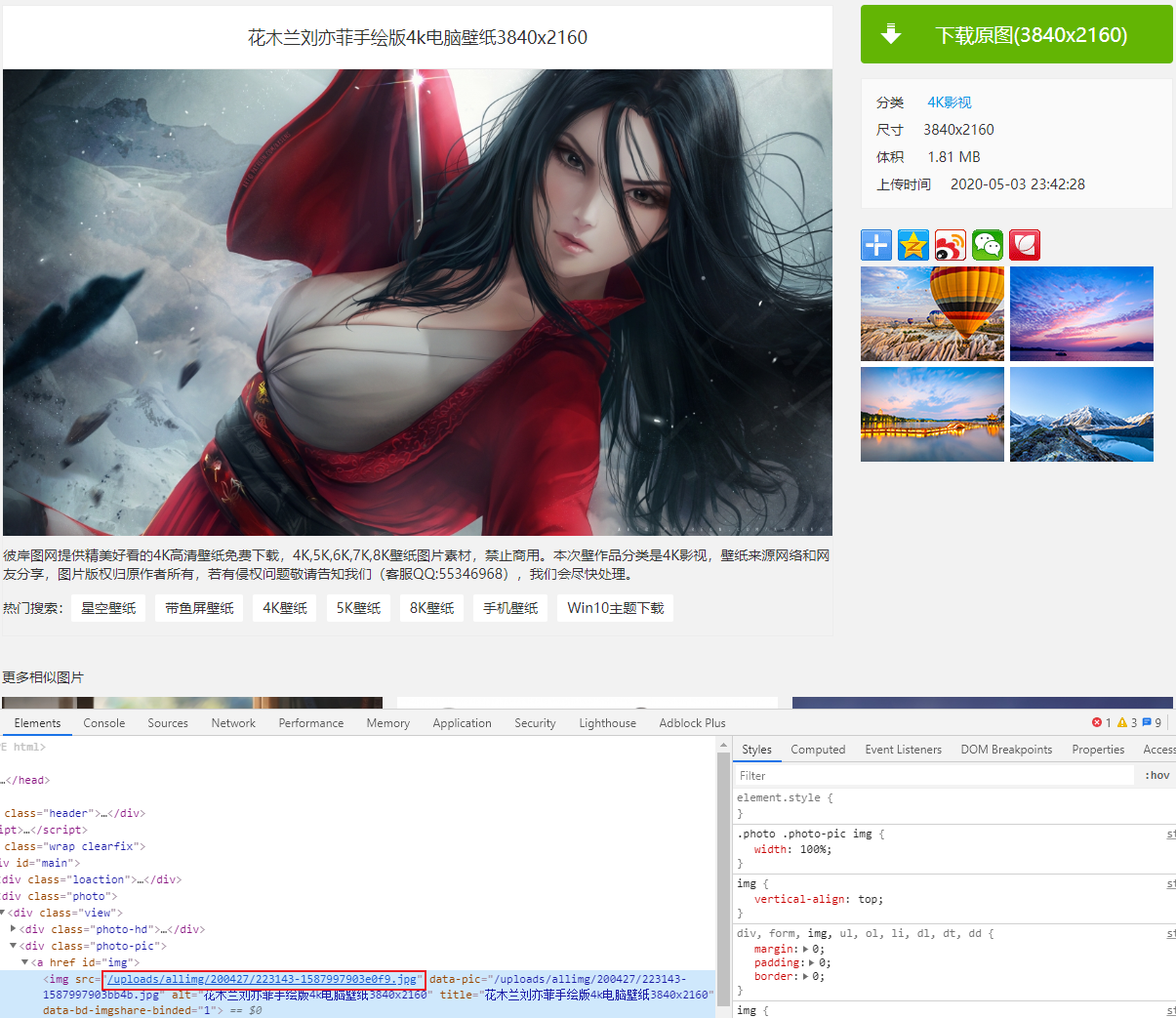
到此,整个网站已经分析完成。
爬取方案
根据分析过程可以很容易想到爬取步骤:
- 获取分类信息,包括名称和链接
- 根据分类链接爬取缩略图信息,逐页爬取
- 逐页爬取过程中,获取大图实际链接
- 下载大图到本地
为了加速爬取过程,我们可以使用多进程,使用Python中的进程池Pool即可。
代码实现
下面通过代码进行实现,为了方便资源共享,减少全局变量或参数传递,我将爬虫封装成一个类Netbian_Spider. 将主页网址和爬虫所需的UA放到初始化信息中。
class Netbian_Spider(object):
def __init__(self):
self.index = 'http://pic.netbian.com'
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}函数定义
在类中,可以先按爬取步骤定义好成员函数,当然在编码过程中可以依情况进行增删改。
def get_path(self, name):
pass
def get_categories(self):
'''get categories of website'''
pass
def spider_by_category(self, category, url):
'''Process function which use to capture images base on category'''
pass
def parse_thumb_page(self, url, first_page=False):
'''parse thumbnail page and get all the detail pages url'''
pass
def parse_detail_page(self, url):
'''parse detail page and get source image url'''
pass
def download_image(self, url, path):
pass下面对爬虫的实现过程进行详细说明。
保存路径
首先确定图片的保存路径,根目录为~/Pictures/python/netbian,windows对应用户默认的图片目录,linux用户也是同样。
调用get_path会在根目录下会根据分类名称name新建子文件夹。
def get_path(self, name):
home_path = os.path.expanduser('~')
path = os.path.join(home_path, 'Pictures/python/netbian/' + name)
if not os.path.isdir(path):
os.makedirs(path)
return os.path.realpath(path)获取分类信息
按照前面的分类,爬虫第一步是爬取分类信息,我们使用yield定义一个生成器,逐个返回获取到的分类名称和分类网址。
def get_categories(self):
'''get categories of website'''
res = requests.get(self.index, headers=self.headers)
doc = html.fromstring(res.content)
categories = doc.xpath('//div[contains(@class, "classify")]/a')
for category in categories:
name = category.xpath('text()')[0]
url = category.xpath('@href')[0]
yield name, url按分类逐页爬取
得到分类页面url后,通过后续实现的page_thumb_page解析分类页面得到
- 大图详细页面链接
detail_pages - 每个分类的总页面数量
page_cnt
之后就逐页爬取大图并下载到本地,直到所有页面都爬取完成。
def spider_by_category(self, category, url):
'''Process function which use to capture images base on category'''
path_category = self.get_path(category)
detail_pages, page_cnt = self.parse_thumb_page(url, first_page=True)
img_cnt = 0
page_num = 1
while True:
for page in detail_pages:
img_cnt += 1
print('[{} page-{} img-{}] Parsing page {}'.format(
category, page_num, img_cnt, page))
img_url = self.parse_detail_page(page)
self.download_image(img_url, path_category)
page_num += 1
if page_num > page_cnt:
break
detail_pages = self.parse_thumb_page(
'{}index_{}.html'.format(url, page_num))解析缩略图
在分类页面,也就是缩略图页面,通过前面提及的xpath可以得到所有缩略图对应大图的链接。此外,如果是当前分类的首页,还需要返回分页数。
def parse_thumb_page(self, url, first_page=False):
'''parse thumbnail page and get all the detail pages url'''
res = requests.get(self.index + url, headers=self.headers)
doc = html.fromstring(res.content)
detail_pages = doc.xpath('//div[@class="slist"]//a/@href')
if first_page:
page_cnt = doc.xpath(
'//span[@class="slh"]/following-sibling::a[1]/text()')[0]
return detail_pages, int(page_cnt)
else:
return detail_pages下载大图
大图页面的解析也是一个xpath就搞定了,然后通过requests下载到本地指定路径就ok啦。
def parse_detail_page(self, url):
'''parse detail page and get source image url'''
res = requests.get(self.index + url, headers=self.headers)
doc = html.fromstring(res.content)
img_url = doc.xpath('//*[@id="img"]/img/@src')[0]
return img_url
def download_image(self, url, path):
img_name = url.split('/')[-1]
save_path = os.path.join(path, img_name)
res = requests.get(self.index + url, headers=self.headers, timeout=20)
if res.status_code == 200:
with open(save_path, 'wb') as f:
f.write(res.content)main函数
主函数用到的最关键的知识点就是进程池Pool,使用Pool创建多进程,进程数量由multiprocessing.cpu_conut()决定,也就是PC包含的CPU数量。
主函数首先创建Netbian_Spider类的对象spider,然后获取分类信息。进程池中,每个进程处理一个分类,共12个进程,每次最多执行cpu_count()个进程,剩下的需要前面至少一个执行结束才会开始。
def main():
spider = Netbian_Spider()
categories = spider.get_categories()
p = Pool(cpu_count())
for name, url in categories:
p.apply_async(spider.spider_by_category, args=(name, url))
p.close()
p.join()
print('All Done!')
if __name__ == "__main__":
main()爬取测试
使用python3爬取彼岸图网,共爬取图片17796张,9.18G
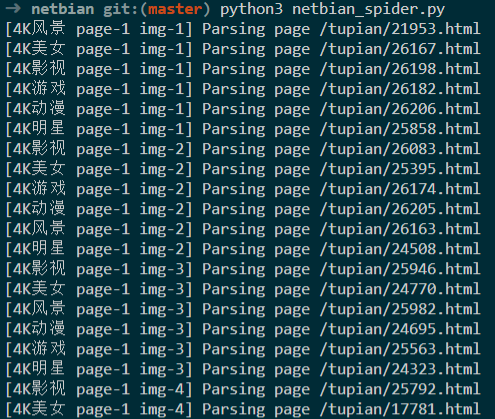
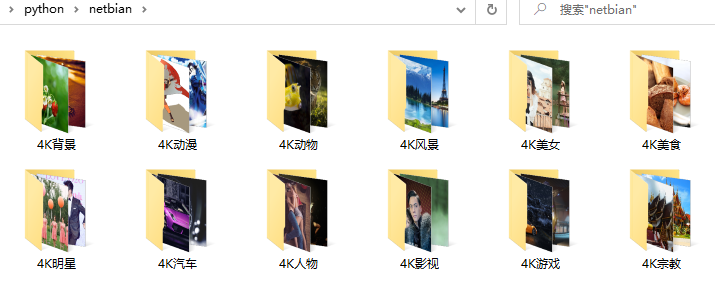
写在最后
该爬虫源码已放置Github项目capturer,欢迎交流。
此外,爬取图片仅供学习,不得商用哦。




